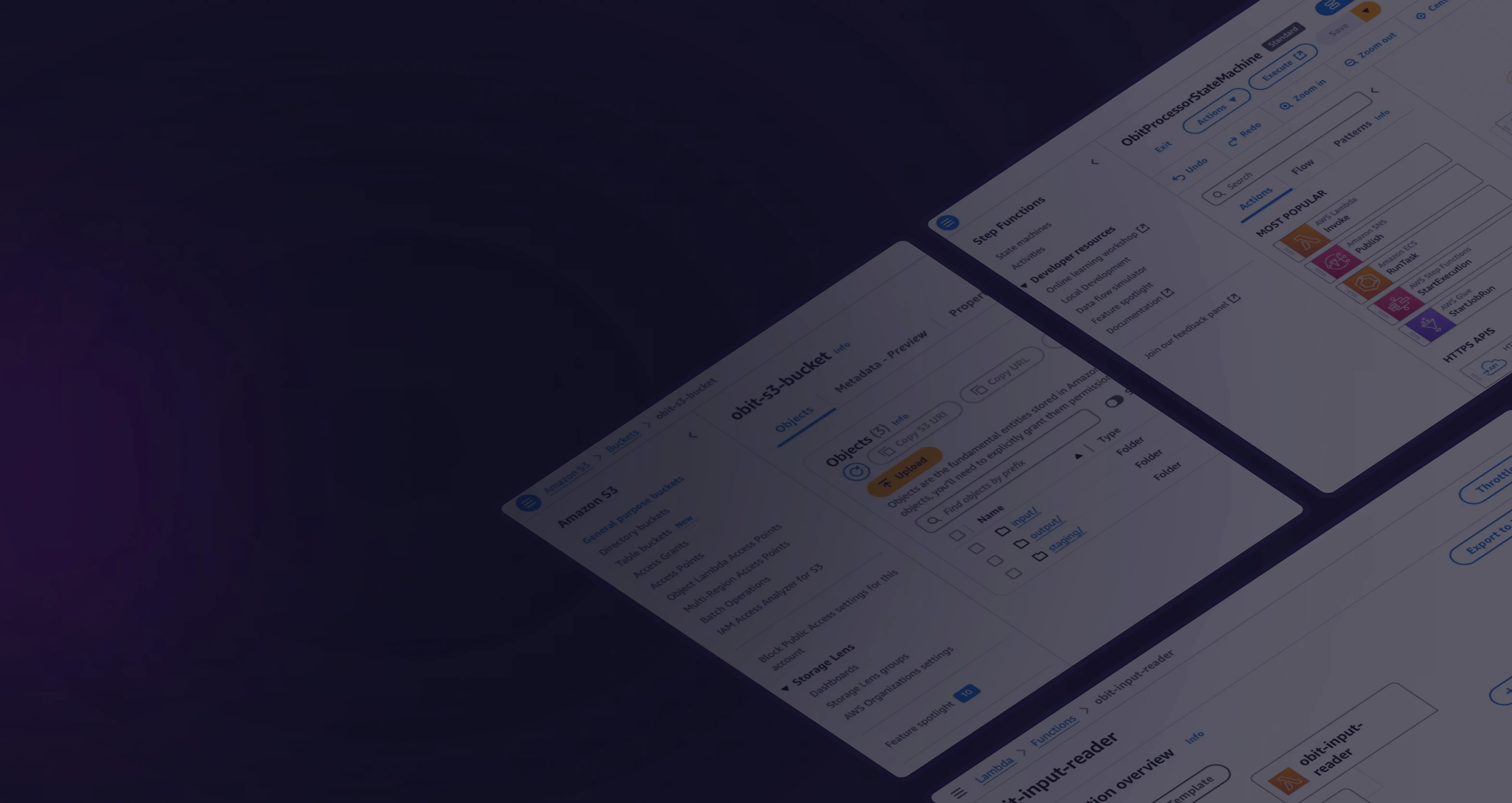
The Background
Our client manages a substantial amount of data (40,000 unique rows per sheet) related to obituaries, requiring precise and efficient processing for accuracy and insights. The original process involved a Python script that:
Accepted an Excel file containing name, city, state, dates of birth and year of death.
Performed searches via Serp API which internally get data from Google, Bing and duck-duck-go for each record.
Used the LLaMA model to compute obituary information.
Processing exceeded AWS Lambda limits (15 minutes), creating bottlenecks.
The Challenge
Time Limits
AWS Lambda’s 15-minute limit blocked full dataset processing.
Scalability
Large Excel files caused performance bottlenecks.
Coordination
Aggregating results reliably into final output was complex
The Solution
01
Split monolithic script into modular components.
02
Used AWS Lambda for parallel processing.
03
Orchestrated workflows using step functions
1. Triggering and Batch Splitting:
An S3 Event triggers a Lambda function when a file is uploaded to an S3 bucket.
The Lambda function splits the Excel file into smaller, manageable batches.
These batches are stored in S3, and their S3 keys are passed to Step Functions.

2. Batch Processing:
Each Lambda function:
- Performs Google and Bing searches for the batch.
- Processes the data using the LLaMA model.
- Writes the results back to S3 and returns the batch's S3 key.


3. Result Aggregation:
- Retrieve all processed batches from S3.
- Combine the data into a single Excel file.
- Write the final output file to S3.

The Results
By adopting a serverless architecture, the processing time for the entire dataset was reduced from 31 days to just 4 hours, while maintaining accuracy and efficiency.
The solution delivered:
Scalability: Parallel batch processing using AWS Step Functions allowed the system to handle large datasets seamlessly.
Cost-Effectiveness: Processing 10,000 records cost only $4, demonstrating the affordability of the serverless approach.
Resilience: Modular Lambda functions enabled efficient retries and reduced the impact of individual task failures.
Processing Time
Reduced from 31 days to 4 hours.
Cost
Only $4 to process 10,000 records.
Operational Savings
50% reduction in manual intervention and infrastructure costs.
The Background
The Challenge
Our Solution
The Results
